New paper by Aditya shows why CNN model observers can be better predictors of radiologist's search than linear models
CNNs discount target-like structures of normal anatomic structures like radiologists do.
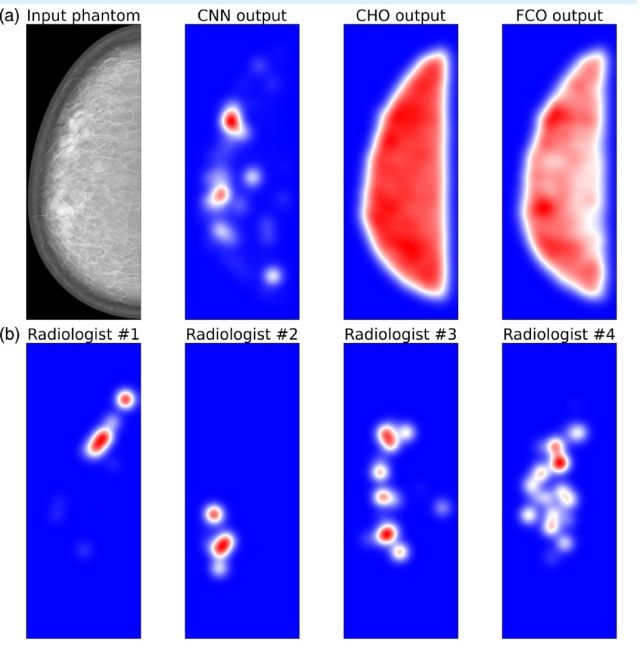
In medical imaging research, scientists often use model observers — computer programs designed to mimic how humans detect signals in noisy images. These models help evaluate new imaging technologies without always needing large groups of human participants. Traditional model observers, such as linear model observers (LMOs), have been successful for simple detection tasks where the location of the target is known. However, they fall short when images are cluttered or when the target could appear anywhere, conditions that resemble real medical search tasks. This study explored whether newer, more biologically inspired models based on artificial intelligence (AI) — specifically convolutional neural networks (CNNs) — can better approximate how radiologists interpret complex medical images.
Radiologists searching for tiny signs of breast cancer—like microcalcifications or small masses—in 3D breast imaging (digital breast tomosynthesis) face a major challenge: normal anatomy can often mimic the appearance of disease. In a new paper in the Journal of Medical Imaging, graduate student Aditya Jonnalagadda ECE UCSB, the VIU lab team , and investigators University of Pennsylvania investigated whether AI systems could evaluate these complex medical images in a way that better matches how humans actually see. They compared two traditional mathematical models of human vision (LMOs) with a more advanced deep learning system known as a CNN.
In the study, both human radiologists and these computational “observers” searched virtual 3D breast phantoms—realistic simulated images containing either small calcifications, larger masses, or no abnormalities at all. The team measured how accurately each system could detect real signals while ignoring false alarms. Traditional LMOs performed well on simple detection tasks where the target location was known in advance, but their performance dropped when the signal could appear anywhere in the image—conditions that mirror real-world search behavior. In contrast, CNNs and human radiologists maintained higher accuracy in these realistic search tasks.
One key discovery was that CNNs, like radiologists, could “discount” normal anatomical structures that merely resemble disease, avoiding the false positives that frequently misled linear models. Eye-tracking data from radiologists confirmed that their gaze tended to linger on the same areas the CNN flagged as suspicious—showing that the network’s responses aligned more closely with human visual attention patterns than older models did. This makes CNNs better tools for understanding and predicting radiologists visual search performance.
This research is important because it shows that modern AI can serve as a more human-like benchmark for medical image quality. As virtual clinical trials increasingly rely on simulated data to test new imaging systems, replacing some expensive human studies, CNN-based “model observers” can provide a more realistic and reliable measure of how well radiologists might perform. Ultimately, this helps scientists design better imaging technologies and improve diagnostic accuracy in breast cancer detection and beyond. The authors also found that the CNN was not able to predict some deficits in human search performance. In particular, it could not predict the difficulty of observers finding small targets during 3D search. This is because humans, but not the CNN, have limitations in the amount of spatial detail they process away from the point of fixation (the visual periphery). This motivates building into the CNN components that limit human vision.