New VIU Lab paper finds selective encoding of object-scene scale consistency in scene-processing brain regions
The findings show how the brain represents object-scene size relationships and may explain why humans often miss objects of atypical scene-relative size during visual search
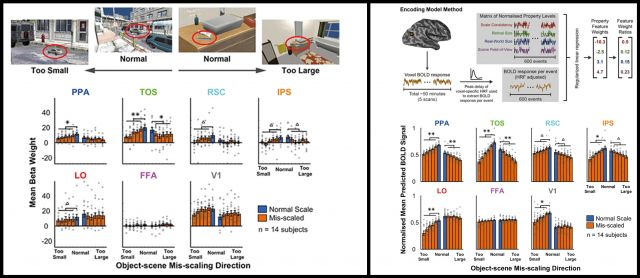
In a new paper ("The transverse occipital sulcus and intraparietal sulcus show neural selectivity to object-scene size relationships") published in the current issue of Communications Biology, first author and former VIU Lab postdoc Dr. Lauren Welbourne, along with co-authors Aditya Jonnalagada (VIU PhD student), Miguel Eckstein (VIU PI), and Barry Giesbrecht (Psychological & Brain Sciences faculty and PI of the UCSB Attention Lab), use functional magnetic resonance imaging (fMRI) to investigate how and where the brain encodes information about an object's size relative to a scene. Previous studies have shown that the human brain relies on these sizes relationships when searching for an object in a complex scene.
In the current study, subjects fixated a dot while a computer-generated scene image was presented for 500ms after which an object was placed on the scene image at the subject's point of fixation for another 500ms. The sizes of the objects and visible scene regions varied in different ways: 1) Retinal Size (size of the object image on the retina varied while the size of the scene image stayed the same), 2) Real-World Size (from physically small objects like toothbrushes to physically large objects like cars), and, 3) Scene Field-Of-View (same retinal size of the object across levels of "zoom" on the scene image). The authors then tested for neural regions that showed a significant effect of Scale Consistency (responses that varied systematically with scene-relative object size, independent of retinal, real-world, or field-of-view size) as well as each size condition using univariate (GLM), multivariate (MVPA), and computational modeling (Encoding Model) techniques. They found that scene-relative object size was most strongly and selectively represented in scene processing areas, especially the transverse occipital sulcus (TOS) and intraparietal sulcus (iPS). Critically, these scene regions were tuned such that they responded maximally to size relationships encountered in the real world, consistent with the learning of representations that are adapted to the (retinal) image statistics experienced during natural behavior.